Overview
Decision Trees
In order to understand what a Random Forest is, and what it does, one must first understand Decision trees. At its most fundamental level, you can think of a decision tree as a “flowchart for predictions”. The tree takes in data in the form of an observation with features, and compares this observation’s values to its specified paths. Take a look at this image showing a decision tree fit on the Titanic dataset and we’ll walk through the logical steps a decision tree model would take during prediction.
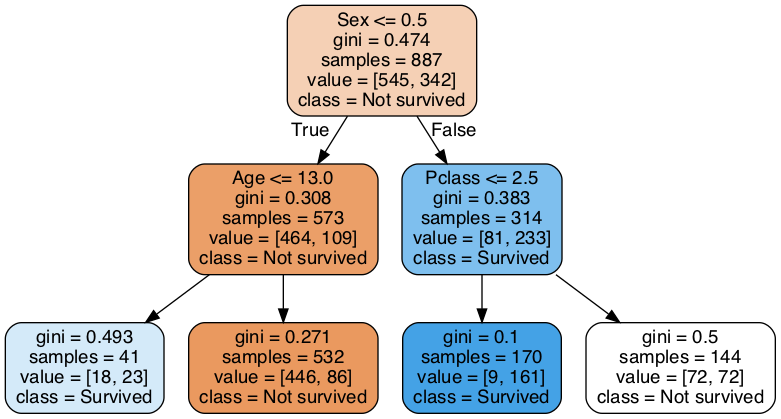
Let’s first create some data to pass through the model. Let’s say we have a 25 year old female who rode the Titanic in 2nd class.
- First, we start at the root node, the top most node. Since sex is encoded as 0 for male, 1 for female, we say that 1 <= 0.5 is False, so we take the right path.
- Secondly, we arrive at a node that asks us about the passenger class. 2 <= 2.5 is True, so we go to the left path.
- This last node doesn’t have a comparison, nor does it have any child nodes, so we consider this a leaf node. We take the class of this node as our prediction, and we predict our 25 year old woman in 2nd class survives.
So this explains what a decision tree is, and how it predicts. But how does it know where to split the data? What’s this “gini” score?
Gini Impurity, along with other impurity metrics like Informational Entropy, categorizes how pure the node is. In the case of Gini Impurity, this value ranges from 0 to 1, with lower values showing higher purity. When we fit the decision tree, it goes through each feature/observation combination and calculates what the impurity of the child nodes would be if it chose to split at that particular point, and it chooses the lowest impurity value to split on.
But as useful as this model is, single decision trees have their flaws. They tend to overfit extremely easily, and as a result (with a couple of exceptions beyond the scope of this post) do not generalize well to unseen data and unseen patterns.
Random Forests
But all is not lost. We can take things a step further. Instead of one decision tree, we can have many of them that all vote on the final prediction. But you might be wondering, “Hey, that method you described above seems pretty deterministic. Wont a lot of decision trees trained on the same data always return the same result?”
The answer is yes, it would. Let’s take a look at what makes Random Forests more than just a bundle of identical trees. Random Forests have the ability to give each tree a somewhat different set of parameters, features, or observations. Each tree having a slightly different set of data makes it able to have slightly different trees.
Now you might be wondering, “If we have a lot of different trees that are giving different results to the same data, isn’t that going to introduce a lot of errors into our predictions?”
The answer is yes, absolutely. It’s introducing those errors by design. The key lies in this statement here: “The average error of a large number of random errors is zero”. If you were to take a look at any single decision tree in this forest after it’s been given a subset of the data, rather than the whole, you might get some useful prediction out of it, you might not. It would certainly be overfit to the subset of the data it was given. But anything it predicts in error should be drowned out by the rest of the forest. Anything it predicts correctly should add to the chorus of correct predictions and also serve to suppress the errors.
Implementing this Model yourself
Before implementing this model yourself, read the Conclusion, Comments, and Considerations section at the end.
The actual implementation of this model is very similar to SKLearn’s own Random Forest Classifier if you have used it. If not, no worries, we’ll go through step by step.
Load in your data
Load in your data into a Pandas dataframe with your method of choice.
import pandas as pd
df = pd.read_csv("YOUR_FILE_OR_URL_HERE.csv")
Clean and Format your Data
This random forest, like SKLearn’s Random Forest, only accepts Numerical data in all of its columns. For categorical features, you will need to encode them, either manually or with a OneHotEncoder or OrdinalEncoder. NaN values will need to be imputed to a numerical value.
All datasets are different, so your cleaning steps will likely be unique to your specific dataset.
Once your dataset is cleaned, you must split it into a training set and a testing set.
from sklearn.model_selection import train_test_split
train, test = train_test_split(df)
features = [LIST OF YOUR FEATURE COLUMNS]
target = 'TARGET_CLASS_COLUMN'
X_train = train[features]
X_test = test[features]
y_train = train[target]
y_test = test[target]
Instantiate the Model
It is necessary to instantiate the model before using it. You also pass in any parameters you may want to have in this instantiation step.
List of parameters and their functions:
- n_trees - Number of decision trees fit by the forest. Default is 100 if not specified.
- n_features - Number of features for each tree to utilize. - Currently will default to all features. Planning on implementing SKLearn’s arguments of ‘auto’, ‘sqrt’, ‘log2’, ‘int’, and ‘float’, all with their own behaviors.
- sample_size - Number of observations each tree will utilize. Default is None, which will utilize all rows in every tree. Planning on implementing SKlearn’s arguments of ‘int’ and ‘float’ as well.
- depth - Maximum depth of each tree. Default value = 10
- min_leaf - Minimum amount of observations per leaf. If a split would leave a leaf with less samples than this value, it aborts and becomes a leaf itself. Default value = 5
- random_seed - Specifies a random seed, for reproducibility. Default Value = 1333
rf_model = RandomForestClassifer(n_trees=95, depth=15)
Fit the model
In this step we will be telling our model to make our decision trees, and prepare to receive data for predictions.
rf_model.fit(X_train, y_train)
Get your predictions
Now we can get our predictions from our model.
y_pred = rf_model.predict(X_test)
And from this point we can use the included Accuracy score function, or the one in sklearn.metrics
print("Accuracy Score: ", accuracy_score(y_test, y_pred))
And there you have it. You successfully ran my Random Forest model.
Conclusion, comments, and considerations.
The first major thing to note, especially if you’re coming from the warning at the beginning of the Implementation section, is that this model is far from perfect. Let’s take a look at some comparisons between my Random Forest model and SKLearn’s Random Forest. All of the below will have been run on the common Iris dataset, averaging over 250 different random seeds.
Accuracy
My model's average accuracy - 0.932368
SKLearn's model's average accuracy - 0.948289
So the accuracy isn’t terrible. It’s about 1.5% less accurate on this dataset. Given the fact that I did not use the standard Gini Impurity, this is not terribly surprising.
Run Time
My model's average run time - 6.7476 seconds
SKLearn's model's average run time - 0.2301 seconds
Oh dear… On the Iris dataset, my model takes 25-30x longer than SKlearn’s model. I’m almost certain that SKLearn implements a much more efficient search algorithm in determining the point of lowest impurity, perhaps a binary search, rather than an exhaustive linear search like I am doing.
Final Thoughts
All that being said, it’s important to note that this is one person’s work, over one week. Functionality came first, and like explained above, it was more complex than I original expected.
What do we do from here? The easiest place to start would be to incorporate the feature/observation subsetting parameters, but the most critical place to start is the time complexity issue. With more time and effort, I could refactor the code for runtime optimization, perhaps implementing a binary search like I mentioned earlier.
All in all I’m rather satisfied with where I’m leaving this project, in terms of something I can point at and show its functionality.
Links
Github Repository - https://github.com/VegaSera/RandomForestClassifier
My Portfolio - https://vegasera.github.io